

久闻CUDA大名,恰好今天要写数字图像处理的作业,不妨来试一试。
首先给出我看的一篇参考文章:http://www.mamicode.com/info-detail-327339.html
截至目前,CUDA的SDK版本号为7.5(正式版)和8.0(RC)。推荐使用7.5,但正式版不支持Visual Studio 2015,只好用了8.0。8.0下载需要注册,而且下载时会出现问题进度卡在60%,貌似是因为链接有生存时间,而我的网速不够快……后来发现先wget到服务器上再从服务器下载到本地就可以了。
OK,安装过程很傻瓜化的,一路next注意下警告就好。安装完毕后进Visual Studio新建项目,发现多出来了CUDA这一项。就是这个:
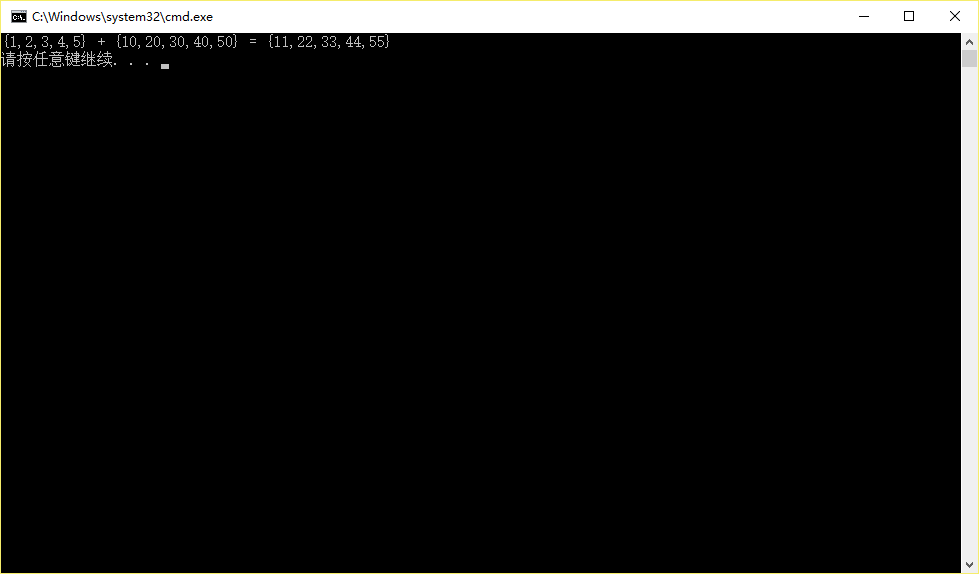
直接确定就好了,没什么多余的设置。建立新工程后,自带了一个例程,把两个向量相加求和的小程序。直接编译运行,若能够正常运行,则说明环境没有问题了。
顺便一提,在安装好了CUDA Toolkit后,VS的菜单栏上应该会多出来一个Nsight,它是用来调试内核程序用的,里面有一个System Info,可以看到本机的一些属性。期间会提示连接不安全,忽略即可。直接打到CUDA Devices页面
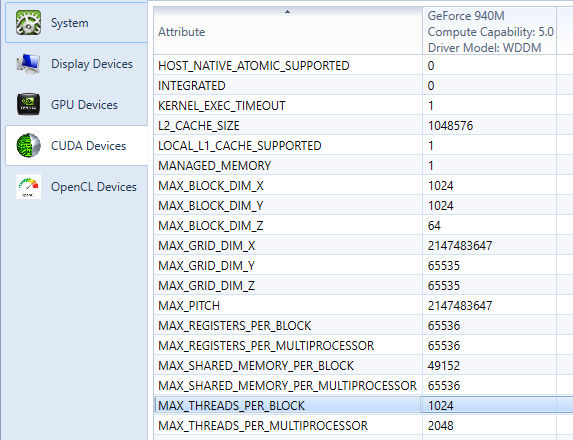
好的,这个MAX_THREADS_PER_BLOCK参数非常重要,以及上面的MAX_BLOCK_DIM_X/Y/Z也很重要,这将关系到你如何划分任务。
先来看看这段例程吧,方便起见直接粘贴过来了
[code language=”cpp”]
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
global void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
c[0], c[1], c[2], c[3], c[4]);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
[/code]
好了,这就是CUDA处理问题的基本流程:设备初始化->分配内存->存入数据->启动内核程序->等待计算结束->取出数据->销毁内存。
先看主函数
[code language=”cpp”]
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
c[0], c[1], c[2], c[3], c[4]);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
[/code]
显然,这个主程序没有做太多的工作,它只是初始化了三个向量,然后把工作丢给了addWithCuda,并通过返回值来接收错误信息。所以我们继续看这个addWithCuda函数。
[code language=”cpp”]
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
[/code]
好吧,居然用了goto,但问题应该也不大。我们来看看这段程序做了啥:
首先,cudaSetDevice设置了使用哪个设备进行运算;
cudaMalloc分配了设备内存(注意,此指针仅在内核程序中有效,指向一个显存单元,在主机程序部分无效);
cudaMemcpy用于传送数据;
之后调用内核函数,要注意,内核函数的调用与主机函数略有不同,是这样子的
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
多了一个<<<Block_Num, Thread Num>>>,这两个参数用于描述任务应当怎么分配到内核上面去,这部分之后解释。
随后是一个cudaDeviceSynchronize,这个用于等待内核函数执行完毕。
之后又是cudaMemcpy,以及cudaFree,用于把数据复制回来并释放内存。
OK,这就是CUDA最最最基本的流程。
我们最后再看一看内核函数,是这样子的
[code language=”cpp”]
global void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
[/code]
这个函数相当简单,输入三个数组,等等,那并行处理的时候线程怎么知道自己的身份呢?它怎么知道该加哪一个?没问题的,threadIdx这个变量存储了本线程的身份信息,在这里我们让第i个线程来操作向量的第i个元素,实现了并行处理。
还记得前面提到过的MAX_THREADS_PER_BLOCK和MAX_BLOCK_DIM_X/Y/Z吗?看名字就知道了,MAX_THREADS_PER_BLOCK描述了每个Block内最多有多少线程,尽管你在分配时可以使用dim3把线程分配成三个维度,但总共不能超过那个上限。如果你只是在自己的机子上算点东西,直接查出来写上就好了;如果你还想在别的机子上运行,那么你最好用cudaGetDeviceProperties这个函数来得到当前设备的信息。
假如我的线程超过这个数怎么办?
没问题,用前面的block参数,然后在内核函数中用blockIdx来获取自己的身份。与线程数限制不太一样,block的限制是分维度的,存储在MAX_BLOCK_DIM_X/Y/Z里面。不过不同block似乎会分配在不同的大核上,无法共享内存,也无法进行同步,但可以进行原子操作。
block与thread的组织情况如下图所示:

好了,现在来点实用点的东西吧。下面这个程序实现了均值滤波,每个线程处理一个点,图像的载入和显示由OpenCV来处理。注意block与thread的分配,以及越界的处理。另外为了图省事,我没做错误处理什么的,直接拿去用搞蓝屏了别来找我……
[code language=”cpp”]
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <opencv2\opencv.hpp>
using namespace cv;
global void cudaBlur(uchar src, uchar *dst, long long start, int rows, int cols, int r=1) {
//注意这个传入的start没用,最开始是因为用for循环执行,每次1个块1024个线程,
//所以要告诉内核函数每次从哪个位置开始计算,现在直接用blockIdx来获得身份信息。
start = (long long)blockIdx.y * 1024 * 1024 + blockIdx.x * 1024;
if (start + threadIdx.x > rowscols) return;
int x = (start + threadIdx.x) / cols;
int y = (start + threadIdx.x) % cols;
int sums = 0;
int count = 0;
for (int i = x – r; i <= x + r; ++i)
for (int j = y – r; j <= y + r; ++j) {
if (i < 0)
break;
if (j < 0) continue; if (j >= cols)
break;
if (i >= rows)
break;
++count;
sums += src[icols + j];
}
dst[xcols + y] = sums / count;
}
Mat RAW;
Mat result;
uchar* devRAW = nullptr;
uchar* devResult = nullptr;
void fn(int , void) {
int window = getTrackbarPos("r", "result");
Mutex mu;
mu.lock();
//块数太多,必须要二位布局了
cudaBlur <<< dim3(1024, long long(RAW.rows)RAW.cols / 1024 / 1024 + 1, 1), 1024 >>>(devRAW, devResult, 0, RAW.rows, RAW.cols,window);
cudaDeviceSynchronize();
for (int i = 0; i < RAW.rows; ++i) {
cudaMemcpy((void)result.ptr(i), (void)(devResult + i*RAW.cols), RAW.cols, cudaMemcpyDeviceToHost);
}
mu.unlock();
imshow("result", result);
}
int main()
{
RAW = imread("Hosho.jpg",CV_LOAD_IMAGE_GRAYSCALE);
cudaSetDevice(0);
cudaMalloc<uchar>(&devRAW, RAW.rowsRAW.cols);
cudaMalloc<uchar>(&devResult, RAW.rowsRAW.cols);
for (int i = 0; i < RAW.rows; ++i) {
cudaMemcpy((void)(devRAW+iRAW.cols), (void*)RAW.ptr(i), RAW.cols, cudaMemcpyHostToDevice);
}
result = Mat(RAW.rows, RAW.cols, CV_8UC1);
imshow("result", RAW);
int a = 0;
createTrackbar("r", "result", &a, 40, fn);
waitKey(0);
blur(RAW, result, Size(3, 3));
cudaFree(devRAW);
cudaFree(devResult);
return 0;
}
[/code]
好的,就是这样子了。现在已经对CUDA有了一点很肤浅的认识了xD